If a variable is local to a Fortran subroutine (i.e., not in a module or a COMMON block), the compiler will assume that it cannot be modified by a called subroutine unless it is an actual argument of the call. In the most common linkage convention, the subroutine is expected to save and restore certain registers. Thus, the optimizer will assume that a register which held a valid copy of such a variable before the call will still hold a valid copy on return.
Example
Fortran 90 register optimization --- extreme.
Source compiled as or compiled as
REAL :: buf, b1 REAL :: buf, b1 REAL :: buf, b1
call MPI_IRECV(buf,..req) call MPI_IRECV(buf,..req) call MPI_IRECV(buf,..req)
register = buf b1 = buf
call MPI_WAIT(req,..) call MPI_WAIT(req,..) call MPI_WAIT(req,..)
b1 = buf b1 = register
Example 0
shows extreme, but allowed, possibilities.
MPI_WAIT on a concurrent thread modifies buf
between the invocation of MPI_IRECV and the completion of
MPI_WAIT. But the compiler cannot see any possibility that
buf can be changed after MPI_IRECV has returned,
and may schedule the load of buf earlier than
typed in the source. The compiler has no reason to avoid using a register to
hold buf across the call to MPI_WAIT. It also
may reorder the instructions as illustrated in the rightmost column.
Example
Similar example with MPI_ISEND
Source compiled as with a possible MPI-internal
execution sequence
REAL :: buf, copy REAL :: buf, copy REAL :: buf, copy
buf = val buf = val buf = val
call MPI_ISEND(buf,..req) call MPI_ISEND(buf,..req) addr = &buf
copy = buf copy= buf copy = buf
buf = val_overwrite buf = val_overwrite
call MPI_WAIT(req,..) call MPI_WAIT(req,..) call send(*addr) ! within
! MPI_WAIT
buf = val_overwrite
Due to valid compiler code movement optimizations in Example 0
,
the content of buf may already have been overwritten by the compiler
when the content of buf is sent.
The code movement is permitted because the compiler cannot detect a possible access
to buf in MPI_WAIT (or in a second thread between
the start of MPI_ISEND and the end of MPI_WAIT).
Such register optimization is based on moving code; here, the access to buf was moved from after MPI_WAIT to before MPI_WAIT. Note that code movement may also occur across subroutine boundaries when subroutines or functions are inlined.
This register optimization/code movement problem for nonblocking operations does not occur with MPI parallel file I/O split collective operations, because in the ..._BEGIN and ..._END calls, the same buffer has to be provided as an actual argument. The register optimization / code movement problem for MPI_BOTTOM and derived MPI datatypes may occur in each blocking and nonblocking communication call, as well as in each parallel file I/O operation.
With persistent requests, the buffer argument is hidden from the MPI_START and MPI_STARTALL calls, i.e., the Fortran compiler may move buffer accesses across the MPI_START or MPI_STARTALL call, similar to the MPI_WAIT call as described in the Nonblocking Operations subsection in Section Problems with Code Movement and Register Optimization .
An example with instruction reordering due to register optimization can be found in Section Registers and Compiler Optimizations .
This section is only relevant if the MPI program uses a buffer argument to an MPI_SEND, MPI_RECV, etc., that hides the actual variables involved in the communication. MPI_BOTTOM with an MPI_Datatype containing absolute addresses is one example. Creating a datatype which uses one variable as an anchor and brings along others by using MPI_GET_ADDRESS to determine their offsets from the anchor is another. The anchor variable would be the only one referenced in the call. Also attention must be paid if MPI operations are used that run in parallel with the user's application.
Example 0 shows what Fortran compilers are allowed to do.
Example
Fortran 90 register optimization.
This source ... can be compiled as:
call MPI_GET_ADDRESS(buf,bufaddr, call MPI_GET_ADDRESS(buf,...)
ierror)
call MPI_TYPE_CREATE_STRUCT(1,1, call MPI_TYPE_CREATE_STRUCT(...)
bufaddr,
MPI_REAL,type,ierror)
call MPI_TYPE_COMMIT(type,ierror) call MPI_TYPE_COMMIT(...)
val_old = buf register = buf
val_old = register
call MPI_RECV(MPI_BOTTOM,1,type,...) call MPI_RECV(MPI_BOTTOM,...)
val_new = buf val_new = register
In Example 0
, the
compiler does not invalidate the register because it cannot
see that MPI_RECV changes the value of buf.
The access to buf is hidden by the use of
MPI_GET_ADDRESS and MPI_BOTTOM.
Example
Similar example with MPI_SEND
This source ... can be compiled as:
! buf contains val_old ! buf contains val_old
buf = val_new
call MPI_SEND(MPI_BOTTOM,1,type,...) call MPI_SEND(...)
! with buf as a displacement in type ! i.e. val_old is sent
!
! buf=val_new is moved to here
! and detected as dead code
! and therefore removed
!
buf = val_overwrite buf = val_overwrite
In Example 0
,
several successive assignments to the same variable buf can be combined in a way
such that only the last assignment is executed.
``Successive'' means that no interfering load access to this variable occurs between the assignments.
The compiler cannot detect that the call to MPI_SEND statement is interfering
because the load access to buf is hidden by the usage of MPI_BOTTOM.
The following sections show in detail how the problems with code movement and register optimization can be portably solved. Application writers can partially or fully avoid these compiler optimization problems by using one or more of the special Fortran declarations with the send and receive buffers used in nonblocking operations, or in operations in which MPI_BOTTOM is used, or if datatype handles that combine several variables are used:
USE mpi_f08
REAL, ASYNCHRONOUS :: b(0:101) ! elements 0 and 101 are halo cells
REAL :: bnew(0:101) ! elements 1 and 100 are newly computed
TYPE(MPI_Request) :: req(4)
INTEGER :: left, right, i
CALL MPI_Cart_shift(...,left,right,...)
CALL MPI_Irecv(b( 0), ..., left, ..., req(1), ...)
CALL MPI_Irecv(b(101), ..., right, ..., req(2), ...)
CALL MPI_Isend(b( 1), ..., left, ..., req(3), ...)
CALL MPI_Isend(b(100), ..., right, ..., req(4), ...)
#ifdef WITHOUT_OVERLAPPING_COMMUNICATION_AND_COMPUTATION
! Case (a)
CALL MPI_Waitall(4,req,...)
DO i=1,100 ! compute all new local data
bnew(i) = function(b(i-1), b(i), b(i+1))
END DO
#endif
#ifdef WITH_OVERLAPPING_COMMUNICATION_AND_COMPUTATION
! Case (b)
DO i=2,99 ! compute only elements for which halo data is not needed
bnew(i) = function(b(i-1), b(i), b(i+1))
END DO
CALL MPI_Waitall(4,req,...)
i=1 ! compute leftmost element
bnew(i) = function(b(i-1), b(i), b(i+1))
i=100 ! compute rightmost element
bnew(i) = function(b(i-1), b(i), b(i+1))
#endif
Each of these methods solves the problems of code movement and register optimization,
but may incur various degrees of performance impact,
and may not be usable in every application context.
These methods may not be guaranteed by the Fortran standard,
but they must be guaranteed by a MPI-3.0 (and later) compliant
MPI library and associated compiler
suite according to the requirements
listed in Section Requirements on Fortran Compilers
.
The performance impact of using MPI_F_SYNC_REG is
expected to be low, that of using module variables or the
ASYNCHRONOUS attribute is expected to be low to medium, and
that of using the VOLATILE attribute is expected to be high or
very high.
Note that there is one attribute that cannot be used for this purpose:
the Fortran TARGET attribute does not solve
code movement problems in MPI applications.
Declaring an actual buffer argument with the ASYNCHRONOUS Fortran attribute in a scoping unit (or BLOCK) informs the compiler that any statement in the scoping unit may be executed while the buffer is affected by a pending asynchronous Fortran input/output operation (since Fortran 2003) or by an asynchronous communication (TS 29113 extension). Without the extensions specified in TS 29113, a Fortran compiler may totally ignore this attribute if the Fortran compiler implements asynchronous Fortran input/output operations with blocking I/O. The ASYNCHRONOUS attribute protects the buffer accesses from optimizations through code movements across routine calls, and the buffer itself from temporary and permanent data movements. If the choice buffer dummy argument of a nonblocking MPI routine is declared with ASYNCHRONOUS (which is mandatory for the mpi_f08 module, with allowable exceptions listed in Section MPI for Different Fortran Standard Versions ), then the compiler has to guarantee call by reference and should report a compile-time error if call by reference is impossible, e.g., if vector subscripts are used. The MPI_ASYNC_PROTECTS_NONBLOCKING is set to .TRUE. if both the protection of the actual buffer argument through ASYNCHRONOUS according to the TS 29113 extension and the declaration of the dummy argument with ASYNCHRONOUS in the Fortran support method is guaranteed for all nonblocking routines, otherwise it is set to .FALSE..
The ASYNCHRONOUS attribute has some restrictions.
Section 5.4.2 of the TS 29113 specifies:
Asynchronous communication is either input communication or output communication. For input communication,
a pending communication affector shall not be referenced, become defined, become undefined, become associated
with a dummy argument that has the VALUE attribute, or have its pointer association status changed. For
output communication, a pending communication affector shall not be redefined, become undefined, or have its
pointer association status changed.''
``Asynchronous communication for a Fortran variable occurs through the action of procedures defined by means
other than Fortran. It is initiated by execution of an asynchronous communication initiation procedure and
completed by execution of an asynchronous communication completion procedure. Between the execution of the
initiation and completion procedures, any variable of which any part is associated with any part of the
asynchronous communication variable is a pending communication affector. Whether a procedure is an asynchronous
communication initiation or completion procedure is processor dependent.
In Example 0 Case (a) on page 0 , the read accesses to b within function(b(i-1), b(i), b(i+1)) cannot be moved by compiler optimizations to before the wait call because b was declared as ASYNCHRONOUS. Note that only the elements 0, 1, 100, and 101 of b are involved in asynchronous communication but by definition, the total variable b is the pending communication affector and is usable for input and output asynchronous communication between the MPI_I... routines and MPI_Waitall. Case (a) works fine because the read accesses to b occur after the communication has completed.
In Case (b), the read accesses to b(1:100) in the loop i=2,99 are read accesses to a pending communication affector while input communication (i.e., the two MPI_Irecv calls) is pending. This is a contradiction to the rule that for input communication, a pending communication affector shall not be referenced. The problem can be solved by using separate variables for the halos and the inner array, or by splitting a common array into disjoint subarrays which are passed through different dummy arguments into a subroutine, as shown in Example 0 .
If one does not overlap communication and computation on the same variable, then all optimization problems can be solved through the ASYNCHRONOUS attribute.
The problems with MPI_BOTTOM, as shown in Example 0 and Example 0 , can also be solved by declaring the buffer buf with the ASYNCHRONOUS attribute.
In some MPI routines, a buffer dummy argument is defined as ASYNCHRONOUS to guarantee passing by reference, provided that the actual argument is also defined as ASYNCHRONOUS.
The compiler may be prevented from moving a reference to a buffer across a call to an MPI subroutine by surrounding the call by calls to an external subroutine with the buffer as an actual argument. The MPI library provides the MPI_F_SYNC_REG routine for this purpose; see Section Additional Support for Fortran Register-Memory-Synchronization .

The call to MPI_F_SYNC_REG(buf) prevents moving the last line before the MPI_WAIT call. Further calls to MPI_F_SYNC_REG(buf) are not needed because it is still correct if the additional read access copy=buf is moved below MPI_WAIT and before buf=val_overwrite.
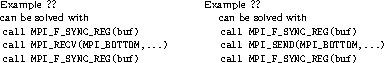
The first call to MPI_F_SYNC_REG(buf) is needed to finish all load and store references to buf prior to MPI_RECV/ MPI_SEND; the second call is needed to assure that any subsequent access to buf is not moved before MPI_RECV/ SEND.

Instead of MPI_F_SYNC_REG, one can also use a user defined external subroutine, which is separately compiled:
subroutine DD(buf)
integer buf
end
Note that if the intent is declared in an explicit interface for the external subroutine, it
must be OUT or INOUT. The subroutine itself may have an empty body, but
the compiler does not know this and has to assume that the buffer may
be altered. For example, a call to
MPI_RECV with MPI_BOTTOM as buffer might be replaced by
call DD(buf)
call MPI_RECV(MPI_BOTTOM,...)
call DD(buf)
Such a user-defined routine was introduced in MPI-2.0 and is still included here
to document such usage in existing application programs although
new applications should prefer MPI_F_SYNC_REG or one of the
other possibilities.
In an existing application, calls to such a user-written routine should
be substituted by a call to MPI_F_SYNC_REG because the
user-written routine may not be implemented in accordance with the
rules specified in Section Requirements on Fortran Compilers
.
An alternative to the previously mentioned methods is to put the buffer or variable into a module or a common block and access it through a USE or COMMON statement in each scope where it is referenced, defined or appears as an actual argument in a call to an MPI routine. The compiler will then have to assume that the MPI procedure may alter the buffer or variable, provided that the compiler cannot infer that the MPI procedure does not reference the module or common block.
The VOLATILE attribute gives the buffer or variable the properties needed to avoid register optimization or code movement problems, but it may inhibit optimization of any code containing references or definitions of the buffer or variable. On many modern systems, the performance impact will be large because not only register, but also cache optimizations will not be applied. Therefore, use of the VOLATILE attribute to enforce correct execution of MPI programs is discouraged.
The TARGET attribute does not solve the code movement problem
because it is not specified for the choice buffer dummy arguments
of nonblocking routines.
If the compiler detects that the application program specifies the
TARGET attribute for an actual buffer argument used
in the call to a nonblocking routine,
the compiler may ignore this attribute if
no pointer reference to this buffer exists.
Rationale.
The Fortran standardization body decided to extend the ASYNCHRONOUS attribute
within the TS 29113 to protect buffers in nonblocking calls
from all kinds of optimization, instead of extending the TARGET attribute.
( End of rationale.)