A correct, portable program must invoke collective communications so that deadlock will not occur, whether collective communications are synchronizing or not. The following examples illustrate dangerous use of collective routines on intracommunicators.
Example
The following is erroneous.
switch(rank) {
case 0:
MPI_Bcast(buf1, count, type, 0, comm);
MPI_Bcast(buf2, count, type, 1, comm);
break;
case 1:
MPI_Bcast(buf2, count, type, 1, comm);
MPI_Bcast(buf1, count, type, 0, comm);
break;
}
We assume that the group of comm is {0,1}.
Two processes execute two broadcast operations in reverse order. If
the operation is synchronizing then a deadlock will occur.
Collective operations must be executed in the same order at all members of the communication group.
Example
The following is erroneous.
switch(rank) {
case 0:
MPI_Bcast(buf1, count, type, 0, comm0);
MPI_Bcast(buf2, count, type, 2, comm2);
break;
case 1:
MPI_Bcast(buf1, count, type, 1, comm1);
MPI_Bcast(buf2, count, type, 0, comm0);
break;
case 2:
MPI_Bcast(buf1, count, type, 2, comm2);
MPI_Bcast(buf2, count, type, 1, comm1);
break;
}
Assume that the group of
comm0 is {0,1}, of comm1 is {1, 2} and of comm2
is {2,0}. If the broadcast is a synchronizing operation, then there
is a cyclic dependency: the broadcast in comm2 completes only
after the broadcast in comm0; the broadcast in comm0
completes only after the broadcast in comm1; and the broadcast
in comm1 completes only after the broadcast in comm2.
Thus, the code will deadlock.
Collective operations must be executed in an order so that no cyclic dependencies occur. Nonblocking collective operations can alleviate this issue.
Example
The following is erroneous.
switch(rank) {
case 0:
MPI_Bcast(buf1, count, type, 0, comm);
MPI_Send(buf2, count, type, 1, tag, comm);
break;
case 1:
MPI_Recv(buf2, count, type, 0, tag, comm, status);
MPI_Bcast(buf1, count, type, 0, comm);
break;
}
Process zero executes a broadcast, followed by a blocking send operation.
Process one first executes a blocking receive that matches the send,
followed by broadcast call that matches the broadcast of process zero.
This program may deadlock. The broadcast call on process zero
may block until process one executes the matching
broadcast call, so that the
send is not executed. Process one will definitely block on the
receive and so, in this case, never executes the
broadcast.
The relative order of execution of collective operations and point-to-point operations should be such, so that even if the collective operations and the point-to-point operations are synchronizing, no deadlock will occur.
Example
An unsafe, non-deterministic program.
switch(rank) {
case 0:
MPI_Bcast(buf1, count, type, 0, comm);
MPI_Send(buf2, count, type, 1, tag, comm);
break;
case 1:
MPI_Recv(buf2, count, type, MPI_ANY_SOURCE, tag, comm, status);
MPI_Bcast(buf1, count, type, 0, comm);
MPI_Recv(buf2, count, type, MPI_ANY_SOURCE, tag, comm, status);
break;
case 2:
MPI_Send(buf2, count, type, 1, tag, comm);
MPI_Bcast(buf1, count, type, 0, comm);
break;
}
All three processes participate in a broadcast. Process 0 sends a message to
process 1 after the broadcast, and process 2 sends a message
to process 1 before
the broadcast. Process 1 receives before and after the broadcast, with a
wildcard source argument.
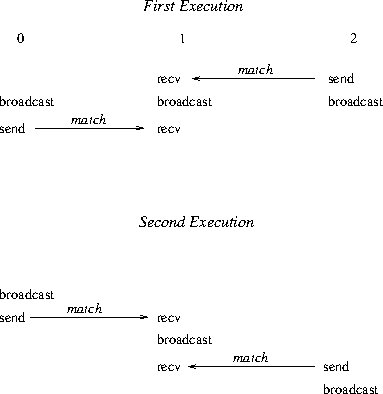
Two possible executions of this program, with different matchings of sends and receives, are illustrated in Figure 12 . Note that the second execution has the peculiar effect that a send executed after the broadcast is received at another node before the broadcast. This example illustrates the fact that one should not rely on collective communication functions to have particular synchronization effects. A program that works correctly only when the first execution occurs (only when broadcast is synchronizing) is erroneous.
Finally, in multithreaded implementations, one can have more than one, concurrently executing, collective communication call at a process. In these situations, it is the user's responsibility to ensure that the same communicator is not used concurrently by two different collective communication calls at the same process.
Advice
to implementors.
Assume that broadcast is implemented using point-to-point MPI communication. Suppose the following two rules are followed.
It is the implementor's responsibility to
ensure that point-to-point messages are not confused with collective
messages. One way to accomplish this is, whenever a communicator is
created, to also create a ``hidden communicator'' for collective communication.
One could achieve a similar
effect more cheaply, for example, by using a hidden
tag or context bit to indicate
whether the communicator is used for point-to-point or collective
communication.
( End of advice to implementors.)
Example
Blocking and nonblocking collective operations can be interleaved, i.e., a blocking collective operation can be posted even if there is a nonblocking collective operation outstanding.
MPI_Request req; MPI_Ibarrier(comm, &req); MPI_Bcast(buf1, count, type, 0, comm); MPI_Wait(&req, MPI_STATUS_IGNORE);Each process starts a nonblocking barrier operation, participates in a blocking broadcast and then waits until every other process started the barrier operation. This effectively turns the broadcast into a synchronizing broadcast with possible communication/communication overlap ( MPI_Bcast is allowed, but not required to synchronize).
Example
The starting order of collective operations on a particular communicator defines their matching. The following example shows an erroneous matching of different collective operations on the same communicator.
MPI_Request req;
switch(rank) {
case 0:
/* erroneous matching */
MPI_Ibarrier(comm, &req);
MPI_Bcast(buf1, count, type, 0, comm);
MPI_Wait(&req, MPI_STATUS_IGNORE);
break;
case 1:
/* erroneous matching */
MPI_Bcast(buf1, count, type, 0, comm);
MPI_Ibarrier(comm, &req);
MPI_Wait(&req, MPI_STATUS_IGNORE);
break;
}
This ordering would match MPI_Ibarrier on rank 0 with
MPI_Bcast on rank 1 which is erroneous and the program behavior is
undefined. However, if such an order is required, the user must create
different duplicate communicators and perform the operations on them.
If started with two processes, the following program would be correct:
MPI_Request req;
MPI_Comm dupcomm;
MPI_Comm_dup(comm, &dupcomm);
switch(rank) {
case 0:
MPI_Ibarrier(comm, &req);
MPI_Bcast(buf1, count, type, 0, dupcomm);
MPI_Wait(&req, MPI_STATUS_IGNORE);
break;
case 1:
MPI_Bcast(buf1, count, type, 0, dupcomm);
MPI_Ibarrier(comm, &req);
MPI_Wait(&req, MPI_STATUS_IGNORE);
break;
}
The use of different communicators offers some flexibility regarding the
matching of nonblocking collective operations. In this sense,
communicators could be used as an equivalent to tags. However,
communicator construction might induce overheads so that this should be
used carefully.
( End of advice to users.)
Example
Nonblocking collective operations can rely on the same progression rules as nonblocking point-to-point messages. Thus, if started with two processes, the following program is a valid MPI program and is guaranteed to terminate:
MPI_Request req;
switch(rank) {
case 0:
MPI_Ibarrier(comm, &req);
MPI_Wait(&req, MPI_STATUS_IGNORE);
MPI_Send(buf, count, dtype, 1, tag, comm);
break;
case 1:
MPI_Ibarrier(comm, &req);
MPI_Recv(buf, count, dtype, 0, tag, comm, MPI_STATUS_IGNORE);
MPI_Wait(&req, MPI_STATUS_IGNORE);
break;
}
The MPI library must progress the barrier in the MPI_Recv
call. Thus, the MPI_Wait call in rank 0 will eventually
complete, which enables the matching MPI_Send so all calls
eventually return.
Example
Blocking and nonblocking collective operations do not match. The following example is erroneous.
MPI_Request req;
switch(rank) {
case 0:
/* erroneous false matching of Alltoall and Ialltoall */
MPI_Ialltoall(sbuf, scnt, stype, rbuf, rcnt, rtype, comm, &req);
MPI_Wait(&req, MPI_STATUS_IGNORE);
break;
case 1:
/* erroneous false matching of Alltoall and Ialltoall */
MPI_Alltoall(sbuf, scnt, stype, rbuf, rcnt, rtype, comm);
break;
}
Example
Collective and point-to-point requests can be mixed in functions that enable multiple completions. If started with two processes, the following program is valid.
MPI_Request reqs[2];
switch(rank) {
case 0:
MPI_Ibarrier(comm, &reqs[0]);
MPI_Send(buf, count, dtype, 1, tag, comm);
MPI_Wait(&reqs[0], MPI_STATUS_IGNORE);
break;
case 1:
MPI_Irecv(buf, count, dtype, 0, tag, comm, &reqs[0]);
MPI_Ibarrier(comm, &reqs[1]);
MPI_Waitall(2, reqs, MPI_STATUSES_IGNORE);
break;
}
The MPI_Waitall call returns only after the barrier and the receive completed.
Example
Multiple nonblocking collective operations can be outstanding on a single communicator and match in order.
MPI_Request reqs[3]; compute(buf1); MPI_Ibcast(buf1, count, type, 0, comm, &reqs[0]); compute(buf2); MPI_Ibcast(buf2, count, type, 0, comm, &reqs[1]); compute(buf3); MPI_Ibcast(buf3, count, type, 0, comm, &reqs[2]); MPI_Waitall(3, reqs, MPI_STATUSES_IGNORE);
Pipelining and double-buffering techniques can efficiently be used to
overlap computation and communication. However, having too many
outstanding requests might have a negative impact on performance.
( End of advice to users.)
Advice
to implementors.
The use of pipelining may generate many outstanding requests. A
high-quality hardware-supported implementation with limited resources
should be able to fall back to a software implementation if its
resources are exhausted. In this way, the implementation could limit the
number of outstanding requests only by the available memory.
( End of advice to implementors.)
Example
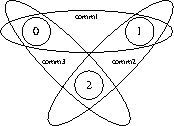
Nonblocking collective operations can also be used to enable simultaneous collective operations on multiple overlapping communicators (see Figure 13 ). The following example is started with three processes and three communicators. The first communicator comm1 includes ranks 0 and 1, comm2 includes ranks 1 and 2, and comm3 spans ranks 0 and 2. It is not possible to perform a blocking collective operation on all communicators because there exists no deadlock-free order to invoke them. However, nonblocking collective operations can easily be used to achieve this task.
MPI_Request reqs[2];
switch(rank) {
case 0:
MPI_Iallreduce(sbuf1, rbuf1, count, dtype, MPI_SUM, comm1, &reqs[0]);
MPI_Iallreduce(sbuf3, rbuf3, count, dtype, MPI_SUM, comm3, &reqs[1]);
break;
case 1:
MPI_Iallreduce(sbuf1, rbuf1, count, dtype, MPI_SUM, comm1, &reqs[0]);
MPI_Iallreduce(sbuf2, rbuf2, count, dtype, MPI_SUM, comm2, &reqs[1]);
break;
case 2:
MPI_Iallreduce(sbuf2, rbuf2, count, dtype, MPI_SUM, comm2, &reqs[0]);
MPI_Iallreduce(sbuf3, rbuf3, count, dtype, MPI_SUM, comm3, &reqs[1]);
break;
}
MPI_Waitall(2, reqs, MPI_STATUSES_IGNORE);
This method can be useful if overlapping neighboring regions (halo
or ghost zones) are used in collective operations. The sequence of the
two calls in each process is irrelevant because the two nonblocking
operations are performed on different communicators.
( End of advice to users.)
Example
The progress of multiple outstanding nonblocking collective operations is completely independent.
MPI_Request reqs[2]; compute(buf1); MPI_Ibcast(buf1, count, type, 0, comm, &reqs[0]); compute(buf2); MPI_Ibcast(buf2, count, type, 0, comm, &reqs[1]); MPI_Wait(&reqs[1], MPI_STATUS_IGNORE); /* nothing is known about the status of the first bcast here */ MPI_Wait(&reqs[0], MPI_STATUS_IGNORE);Finishing the second MPI_IBCAST is completely independent of the first one. This means that it is not guaranteed that the first broadcast operation is finished or even started after the second one is completed via reqs[1].